Stop Relying on Selenium — Use This Instead.

Ever find yourself stuck using Selenium, only to realize there are far better alternatives?
Yeah, been there. 😅
Simulated browsing is slow, clunky, and usually overkill. Nowadays, it's my last resort when nothing else works.
So what do I use instead?
Direct HTTP Requests
If you're serious about scraping, knowing how to perform HTTP requests is a must. Why? Because it's not only simpler to implement, but also much faster.
However, the default requests libraries from Python often get blocked. The usual setup sends headers that clearly identify it as a script.
But don't worry, there are better alternatives:
hrequests
- It's fast, lightweight, and powerful
- It supports TLS fingerprint replication, HTTP/2, and browser-like sessions
- It also mimics real browser behavior
- That means proper headers, cookies, and connection patterns
curl_cffi
- curl_cffi is my go-to tool for advanced scraping 🔥
- It's built to handle the kinds of anti-bot defenses that break regular HTTP clients
- Unlike pure Python libraries, this one goes deeper
- It does everything hrequests does, plus handles JA3 and JA3S fingerprint matching
- Best part? Same requests-style API — no need to learn anything new
Want to impersonate Edge99?
Just do this:
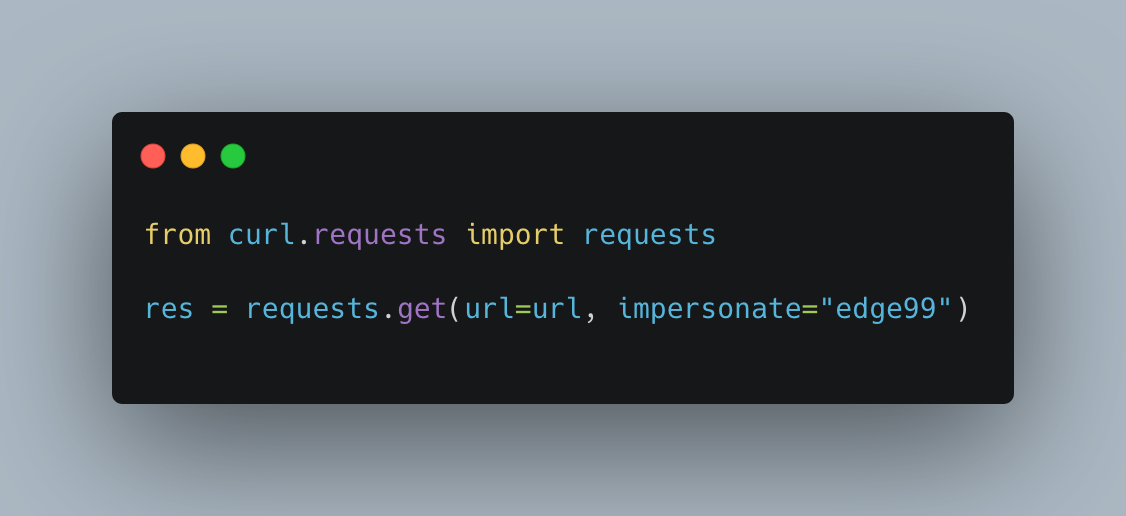
That's it.
You wouldn't believe how many sites that used to block you are suddenly chill with you now.
I'm currently using Yaak — it's clean, fast, and super intuitive. (Postman's solid too, but Yaak fits my workflow better.)
Here's the simplified flow:
1. Open DevTools → Copy a cURL request
2. Open Yaak, and click "Import cURL"
3. Voilà!
All the headers, cookies and parameters will be automatically imported, and now you can easily customize your request.
You can quickly test variations, modify parameters, and see responses in real-time without writing a single line of code.
The visual interface makes it much easier to identify which parts of the request are essential for successful scraping, saving you hours of trial and error in your code.
2. Requests Interception Using Simulated Android Devices
Imagine this scenario:
- You've found a website with incredibly valuable data
- Unfortunately, there's no internal API available (that you can find in DevTools.
- When you try to scrape the site directly, the html content is messy and unstructured.
- Your IP gets flagged, CAPTCHA challenges appear, or the site returns misleading data
Game over? Not quite.
Here's the secret weapon: The same company often has a mobile app that accesses the exact same data. And that changes everything.
Mobile apps typically communicate with private APIs that:
- Have less aggressive anti-bot protection
- Use different authentication mechanisms
- Often contain more structured data than the website
- May include additional endpoints with valuable information not visible on the website
Here’s how I do it step by step:
- Set up a simulated Android device
Start by creating an emulator in Android Studio. I recommend using a Pixel 6 Pro image without the Play Store preinstalled.
This is important because the Play Store often applies certificate pinning to network requests—not just for itself, but sometimes system-wide—making it harder to intercept HTTPS traffic.
Instead of using the Play Store, install Aurora Store on your emulator. Aurora is a privacy-friendly client for the Play Store that lets you download most apps without needing a Google account.
It avoids the bloat and complications that come with Google’s proprietary services, and gives you more control during testing and analysis.
- Set up HTTP interception
This is where HTTP Toolkit shines.
It’s one of the easiest and most effective tools for intercepting HTTP and HTTPS traffic from Android apps.
Why HTTP Toolkit?
- It supports ADB-based setup, so it can inject its own custom system CA certificate into the emulator with just a click.
- It automatically configures everything for you—no root required, no manual installation of certs.
- It has a clean UI with filtering, searching, and live traffic display that’s beginner-friendly but still powerful.
To get started:
- Open HTTP Toolkit on your PC.
- Launch your emulator.
- Connect the emulator via ADB in HTTP Toolkit (it’ll guide you through it).
- Once connected, install your target app in the emulator.
- Use HTTP Toolkit to monitor and intercept its requests in real time.
Step 3: Analyze the traffic
Now comes the fun part—interacting with the app and watching the traffic roll in.
Use the search bar in HTTP Toolkit to filter traffic. Look for specific strings related to the app’s features, endpoints, or anything else you suspect is being sent or received.
For example:
- Search for usernames, API paths, tokens, headers, etc.
- Trigger different features in the app and note how the requests change.
This lets you reverse-engineer how the app communicates with its backend—and possibly identify undocumented endpoints or vulnerabilities.
In some cases, network interception isn’t enough—especially if the app is using strong certificate pinning or encrypting payloads internally.
That’s when reverse engineering the APK becomes useful.
In some cases, network interception isn’t enough—especially if the app is using strong certificate pinning or encrypting payloads internally. That’s when reverse engineering the APK becomes useful.
You might want to look into decompiling the app using tools like JADX or JADX-GUI, exploring its smali or Java code, and finding out how requests are constructed or encrypted.
But that’s a topic for another guide. 😉
3. JSON-LD + Extruct
Here’s a sneaky-good method that flies under most people’s radar:
Extracting structured data directly from JSON-LD.
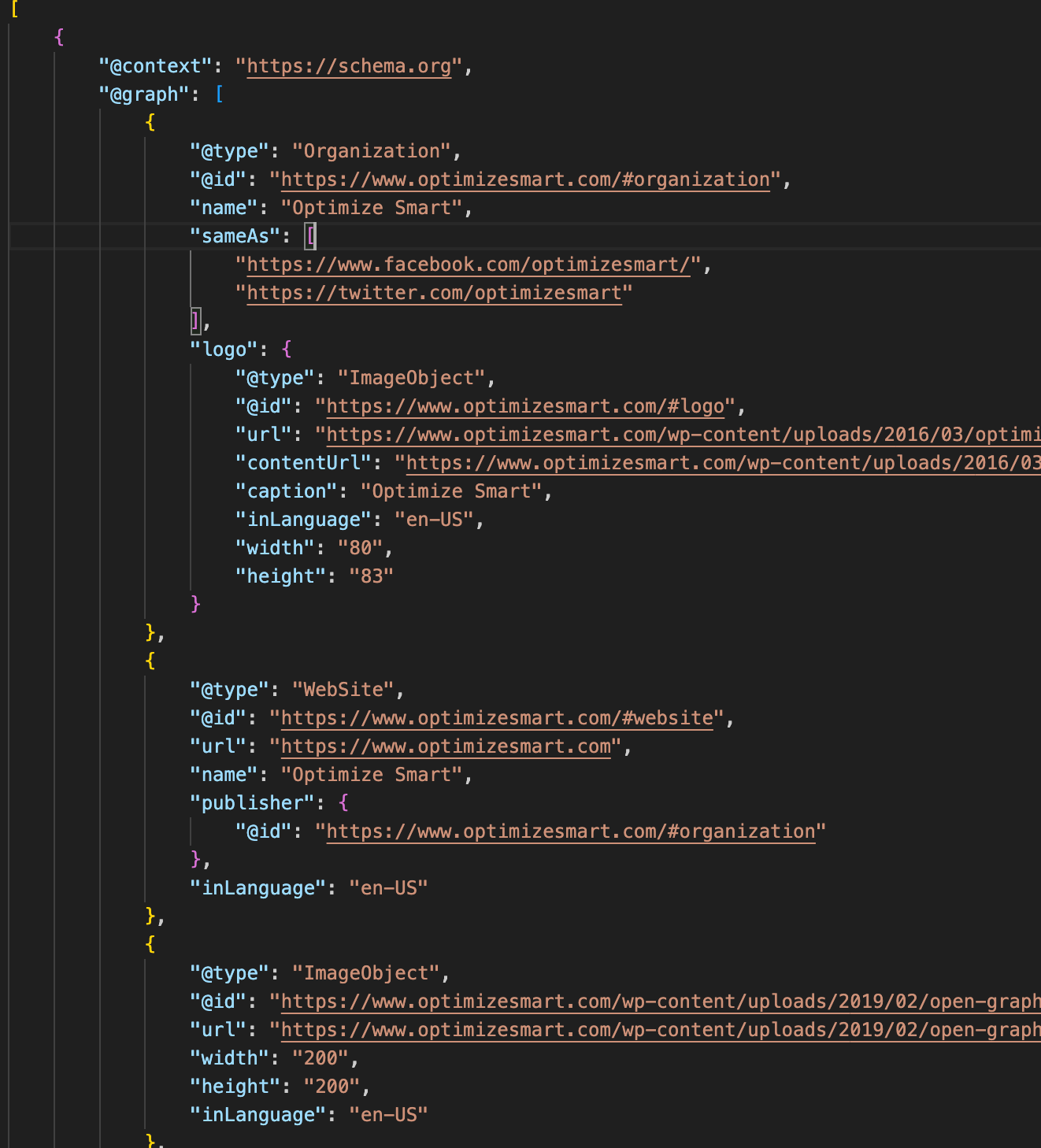
You’ve probably seen those sneaky little blocks hiding in the <head> or <body> of webpages.
They’re typically injected for SEO, but for scrapers? They’re absolute gold.
These blocks often contain clean, structured data in JSON format — things like:
- Product names, descriptions, and prices (on eCommerce sites)
- Article titles, authors, and publish dates (on blogs or news pages)
- Organization info, breadcrumbs, ratings, etc.
Why bother with messy HTML parsing when the site is literally handing you the data in a neat little JSON package?
Skip the DOM tree wrestling match. Just grab what’s already well-organized.
How to extract JSON-LD easily
Use Extruct — a lightweight and powerful Python library designed to extract various types of embedded metadata, including:
- JSON-LD
- Microdata
- RDFa
- Open Graph
- Twitter Cards, and more.
Example usage:
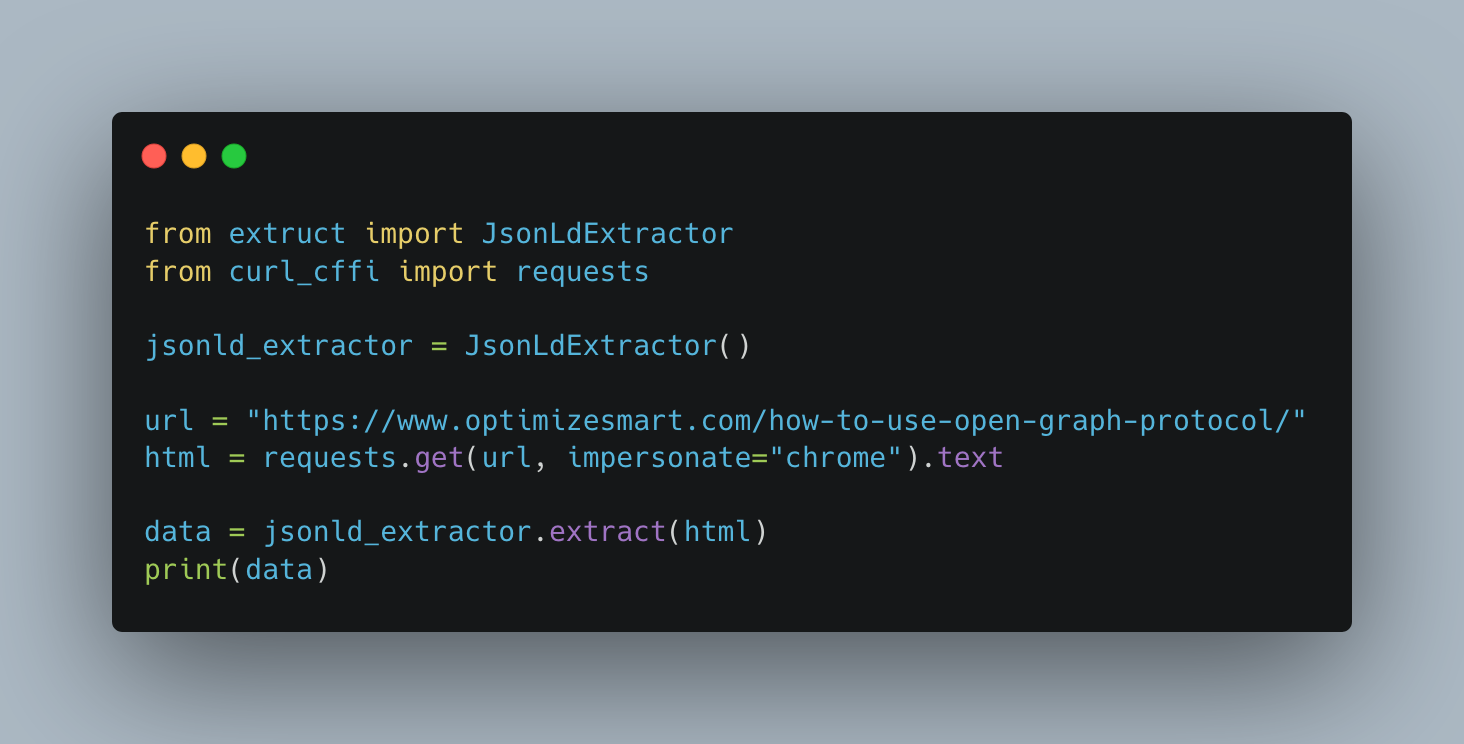
And the output? Magnifient already formatted json.
This gives you structured content without having to manually locate or parse the <script> blocks yourself.
TL;DR
If you’re not using JSON-LD extraction in your scraping toolkit, you’re probably working harder than you need to.
It’s clean, consistent, and often gets you 90% of the data you want — no XPath headaches required.